TAS-LoRA: Transformer Architecture Search with Mixture-of-LoRA Experts
CVPR 2026
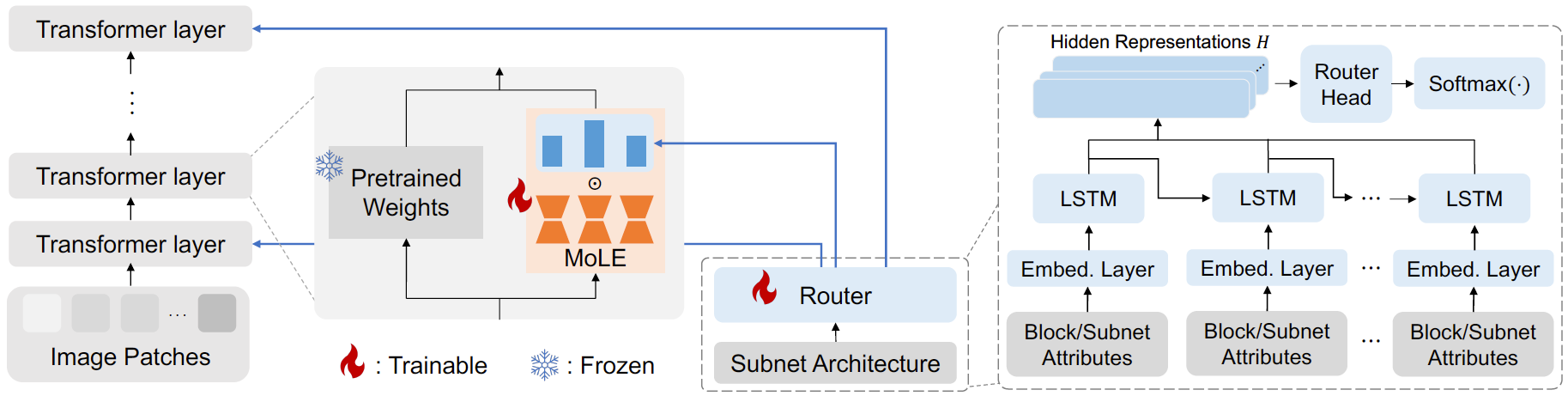
Abstract
Transformer architecture search (TAS) discovers optimal vision transformer (ViT) architectures automatically, reducing human effort to manually design ViTs. However, existing TAS methods suffer from the feature collapse problem, where subnets within a supernet fail to learn subnet-specific features, mainly due to the shared weights in a supernet, limiting the performance of individual subnets. To address this, we propose TAS-LoRA, a novel method that introduces parameter-efficient low-rank adaptation (LoRA) to enable subnet-specific feature learning, while maintaining computational efficiency. TAS-LoRA incorporates a Mixture-of-LoRAExperts (MoLE) strategy, where a lightweight router dynamically assigns LoRA experts based on subnet architectures, and introduces a group-wise router initialization technique to encourage diverse feature learning across experts early in training. Extensive experiments on ImageNet and several transfer learning benchmarks, including CIFAR-10/100, Flowers, CARS, and INAT-19, demonstrate that TAS-LoRA mitigates feature collapse effectively, improving performance over state-of-the-art TAS methods significantly.
Results
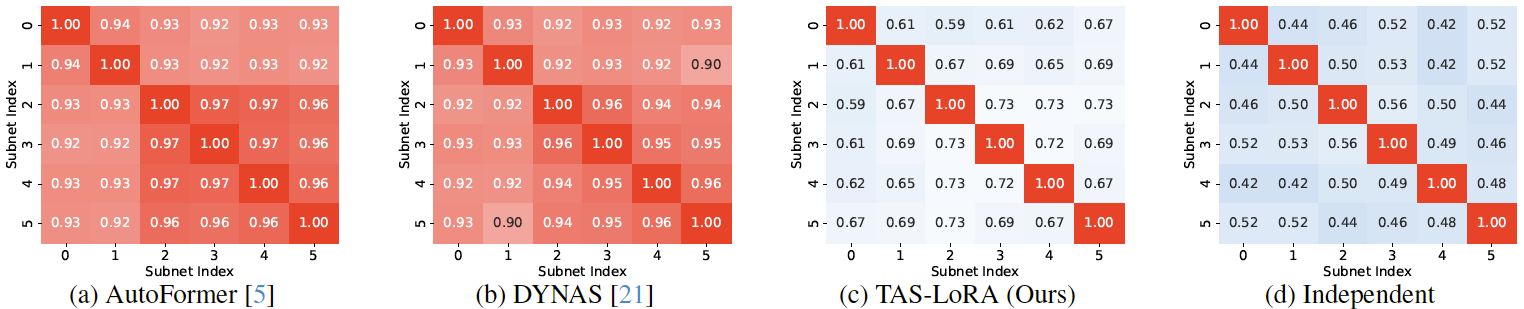
Fig. 1: Feature similarities between subnets trained with different strategies. Six subnets are randomly sampled from each supernet, and average cosine similarity is computed between features from the penultimate-layer: (a) AutoFormer, (b) DYNAS, (c) TAS-LoRA, (d) Subnets trained independently from scratch.
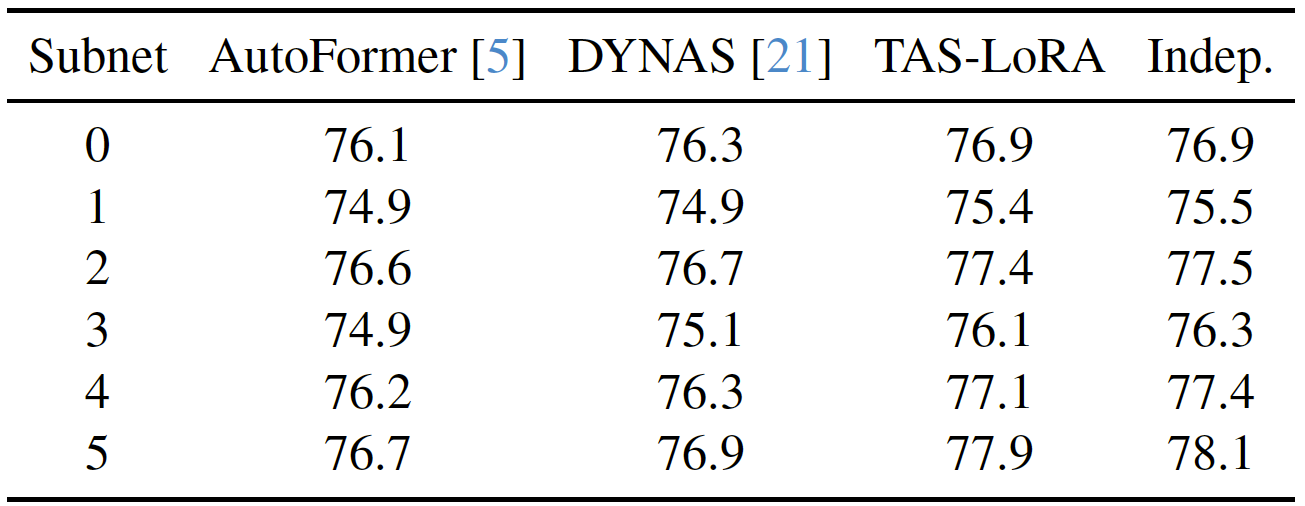
Tab. 1: Top-1 accuracies (%) of six subnets, randomly sampled and trained with different strategies. ”AutoFormer” and ”DYNAS” represent weight-entangled supernets, where all subnets share weights. ”TAS-LoRA” incorporates subnet-specific LoRA modules, while ”Indep.” trains each subnet independently from scratch.
We visualize in Fig. 1 (a-b) cosine similarity between feature representations from six subnets, randomly sampled and trained with weight-entangled TAS approaches, AutoFormer and DYNAS. We can see that feature representations are nearly identical. Subnets trained independently from scratch, however, exhibit significantly lower similarity, suggesting that optimal feature representations vary, according to subnet architectures (Fig. 1(d)). This observation is further supported by the top-1 accuracy in Table 1, where subnets trained via AutoFormer and DYNAS perform notably worse than their counterparts trained from scratch independently. To address this limitation, we propose TAS-LoRA, which encourages subnets to learn more specialized and diverse features. Rather than relying on shared weights solely, TAS-LoRA introduces lightweight, subnet-specific adaptation modules that reduce feature redundancy across subnets (Fig. 1(c)), thereby achieving top-1 accuracies comparable to subnets trained independently from scratch (Table 1).
Paper

Acknowledgements
This work was partly supported by IITP grant funded by the Korea government (MSIT) (No.RS2022-00143524, Development of Fundamental Technology and Integrated Solution for NextGeneration Automatic Artificial Intelligence System, No.2022-0-00124, RS-2022-II220124, Development of Artificial Intelligence Technology for Self-Improving Competency-Aware Learning Capabilities, AI Semiconductor Innovation Lab (Yonsei University)), and the KIST Institutional Program (Project No.2E33001-24-086).