Exploiting a Joint Embedding Space for
Generalized Zero-Shot Semantic Segmentation
ICCV 2021
Abstract
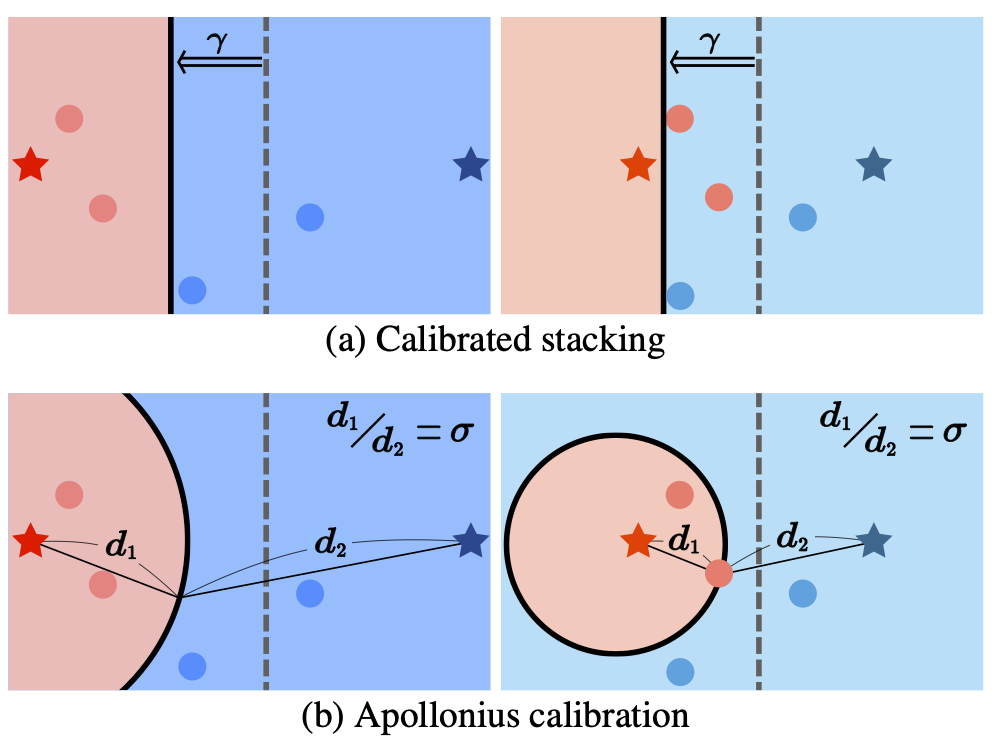
We address the problem of generalized zero-shot semantic segmentation (GZS3) predicting pixel-wise semantic labels for seen and unseen classes. Most GZS3 methods adopt a generative approach that synthesizes visual features of unseen classes from corresponding semantic ones (e.g., word2vec) to train novel classifiers for both seen and unseen classes. Although generative methods show decent performance, they have two limitations: (1) the visual features are biased towards seen classes; (2) the classifier should be retrained whenever novel unseen classes appear. We propose a discriminative approach to address these limitations in a unified framework. To this end, we leverage visual and semantic encoders to learn a joint embedding space, where the semantic encoder transforms semantic features to semantic prototypes that act as centers for visual features of corresponding classes. Specifically, we introduce boundary-aware regression (BAR) and semantic consistency (SC) losses to learn discriminative features. Our approach to exploiting the joint embedding space, together with BAR and SC terms, alleviates the seen bias problem. At test time, we avoid the retraining process by exploiting semantic prototypes as a nearest-neighbor (NN) classifier. To further alleviate the bias problem, we also propose an inference technique, dubbed Apollonius calibration (AC), that modulates the decision boundary of the NN classifier to the Apollonius circle adaptively. Experimental results demonstrate the effectiveness of our framework, achieving a new state of the art on standard benchmarks.
Approach
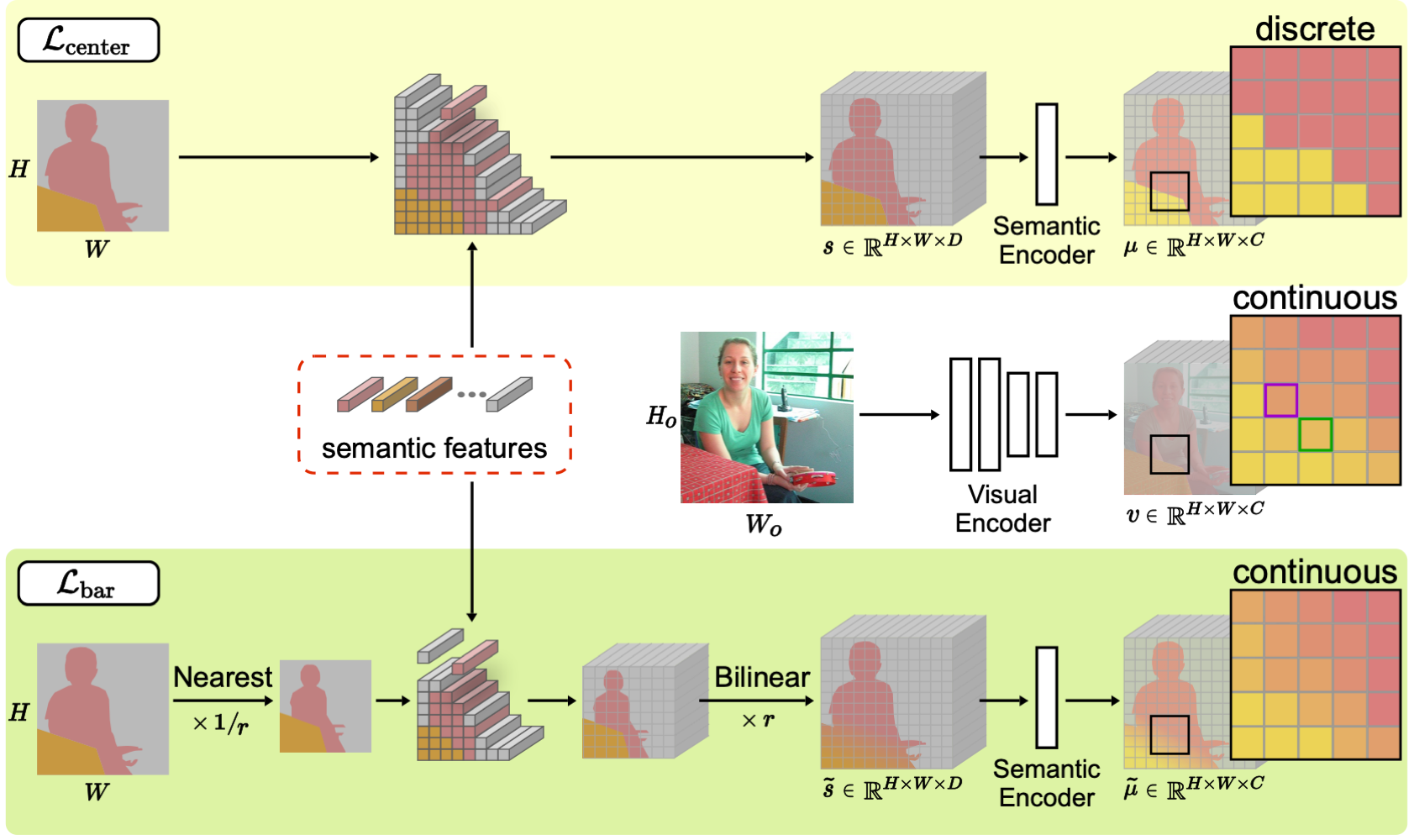
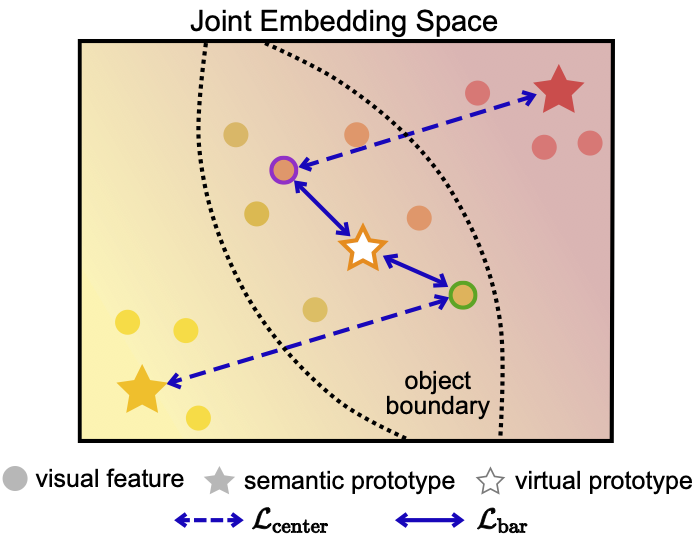
Following the common practice, we divide classes into two disjoint sets, where we denote by \(\mathcal{S}\) and \(\mathcal{U}\) sets of seen and unseen classes, respectively. We train our model including visual and semantic encoders with the seen classes \(\mathcal{S}\) only, and use the model to predict pixel-wise semantic labels of a scene for both seen and unseen classes, \(\mathcal{S}\) and \(\mathcal{U}\), at test time. To this end, we jointly update both encoders to learn a joint embedding space. Specifically, we first extract visual features using the visual encoder. We then input semantic features (e.g., word2vec) to the semantic encoder, and obtain semantic prototypes that represent centers for visual features of corresponding classes. We have empirically found that visual features at object boundaries could contain a mixture of different semantics, which causes discrepancies between visual features and semantic prototypes. To address this, we propose to use linearly interpolated semantic prototypes, and minimize the distances between the visual features and semantic prototypes. We also encourage the relationships between semantic prototypes to be similar to those between semantic features explicitly. At test time, we use the semantic prototypes of both seen and unseen classes as a NN classifier without re-training. To further reduce the seen bias problem, we modulate the decision boundary of the NN classifier adaptively.
Paper

|
D. Baek, Y. Oh, B. Ham Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation In IEEE/CVF International Conference on Computer Vision (ICCV) , 2021 [arXiv][Code] |
BibTeX
@InProceedings{Baek_2021_ICCV,
author = {Baek, Donghyeon and Oh, Youngmin and Ham, Bumsub},
title = {Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation},
booktitle = {ICCV},
year = {2021}
}
Acknowledgements
This research was partly supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (NRF-2019R1A2C2084816) and Yonsei University Research Fund of 2021 (2021-22-0001).