Network Quantization with Element-wise Gradient Scaling (CVPR 2021)
Authors
Abstract
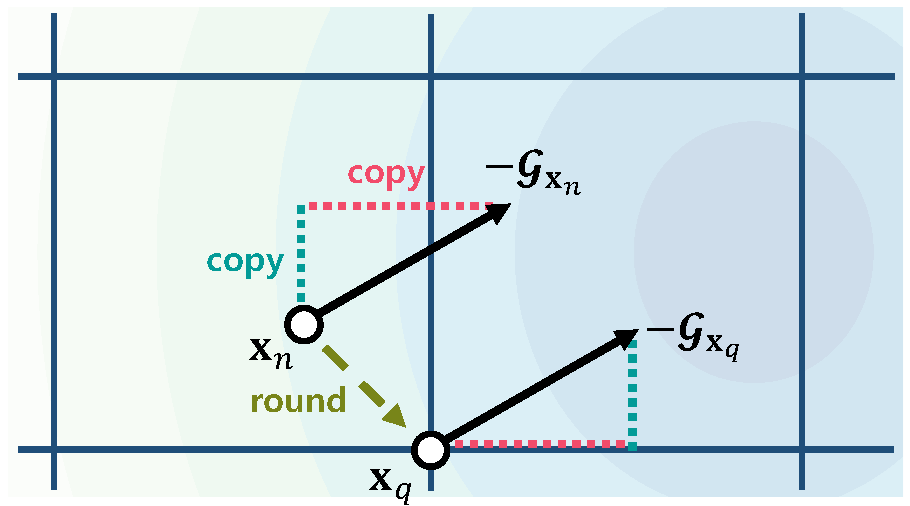
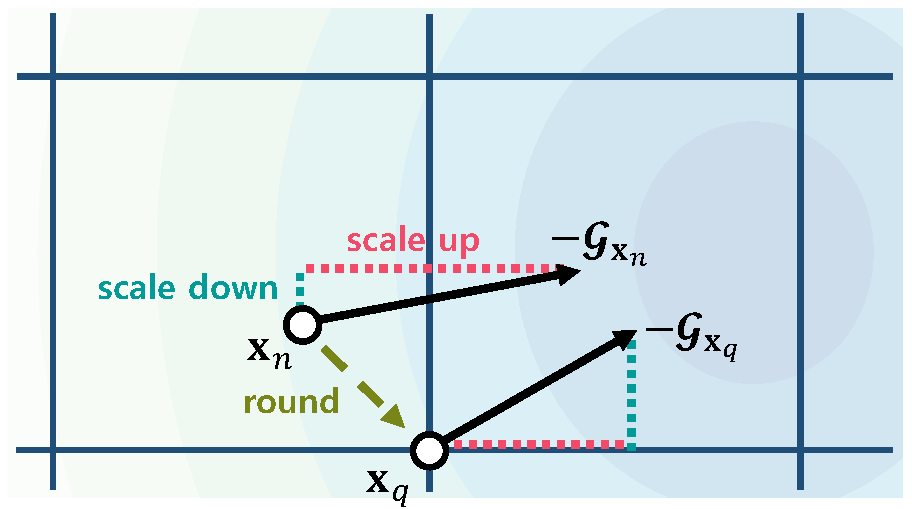
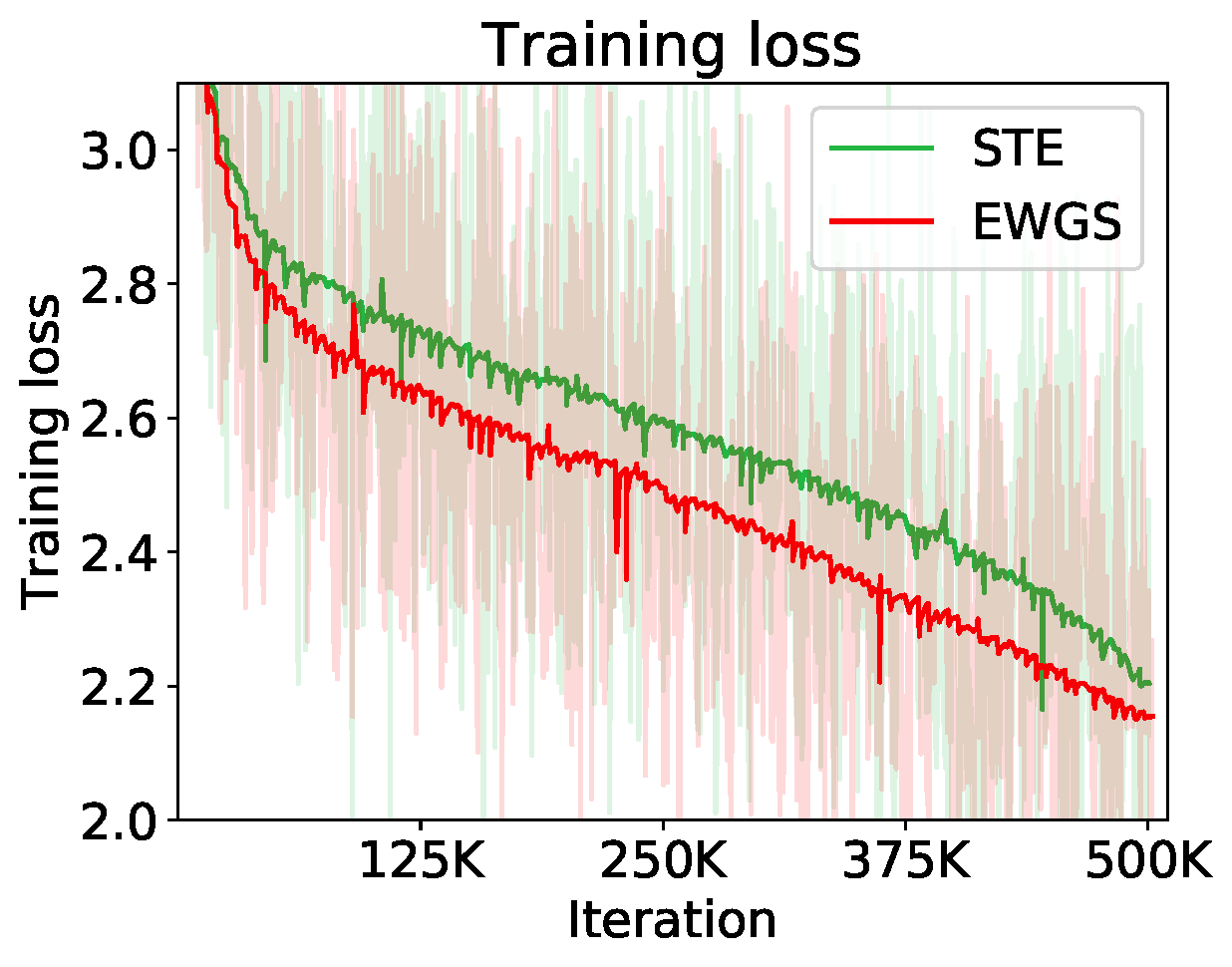
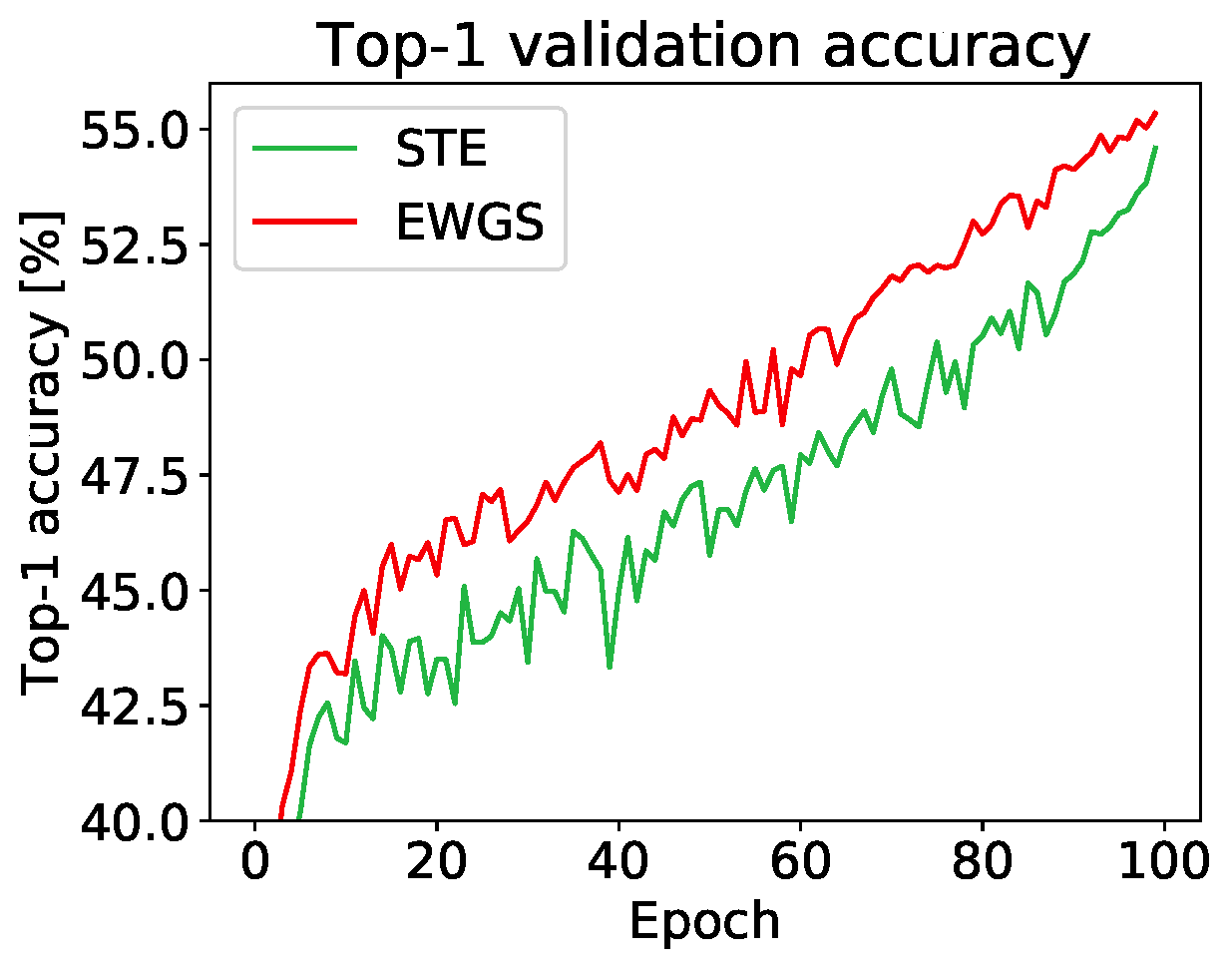
Network quantization aims at reducing bit-widths of weights and/or activations, particularly important for implementing deep neural networks with limited hardware resources. Most methods use the straight-through estimator (STE) to train quantized networks, which avoids a zero-gradient problem by replacing a derivative of a discretizer (i.e., a round function) with that of an identity function. Although quantized networks exploiting the STE have shown decent performance, the STE is sub-optimal in that it simply propagates the same gradient without considering discretization errors between inputs and outputs of the discretizer. In this paper, we propose an element-wise gradient scaling (EWGS), a simple yet effective alternative to the STE, training a quantized network better than the STE in terms of stability and accuracy. Given a gradient of the discretizer output, EWGS adaptively scales up or down each gradient element, and uses the scaled gradient as the one for the discretizer input to train quantized networks via backpropagation. The scaling is performed depending on both the sign of each gradient element and an error between the continuous input and discrete output of the discretizer. We adjust a scaling factor adaptively using Hessian information of a network. We show extensive experimental results on the image classification datasets, including CIFAR-10 and ImageNet, with diverse network architectures under a wide range of bit-width settings, demonstrating the effectiveness of our method.
Method

(a) The sign of an update for the discrete value

(b) The sign of an update for the discrete value
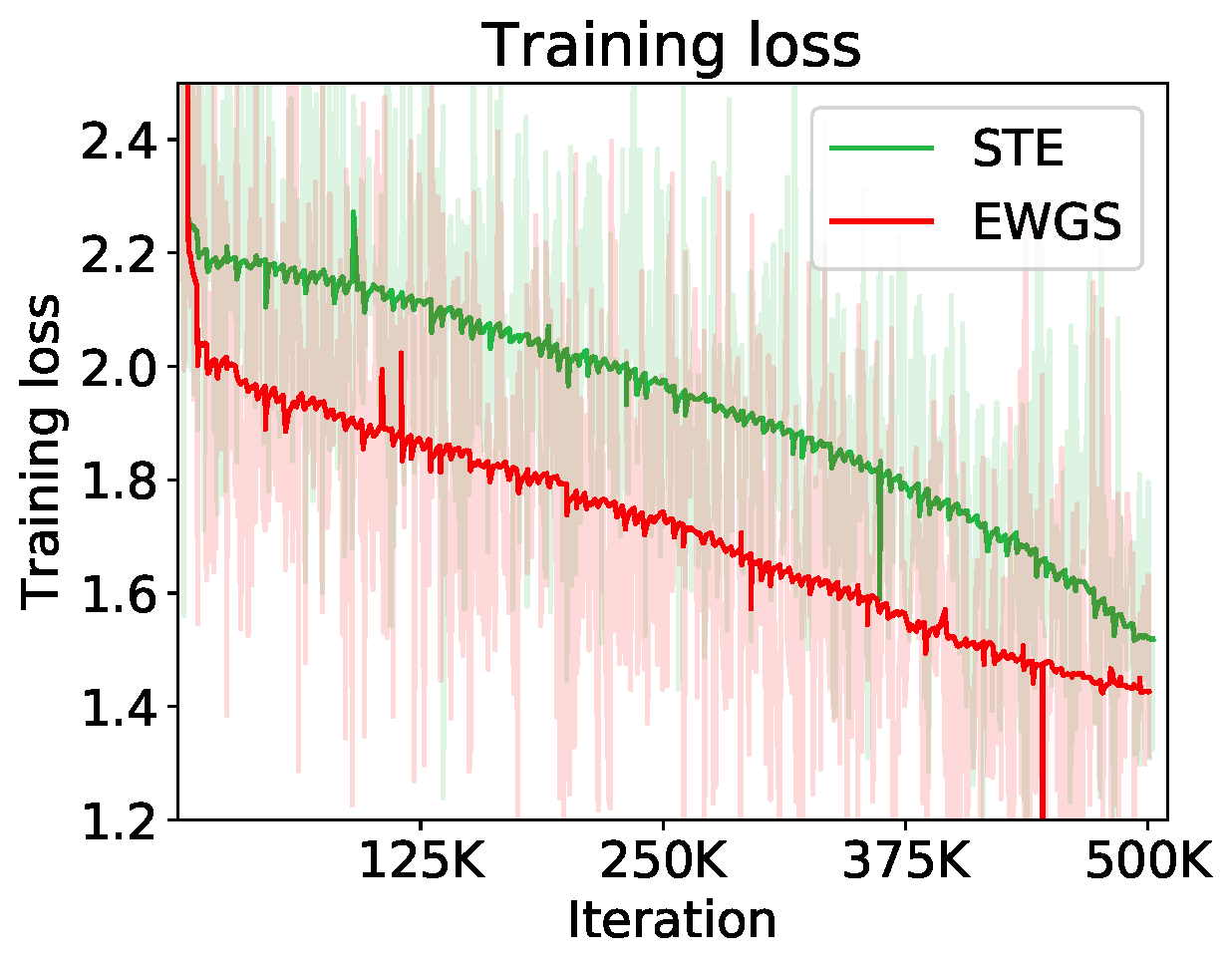
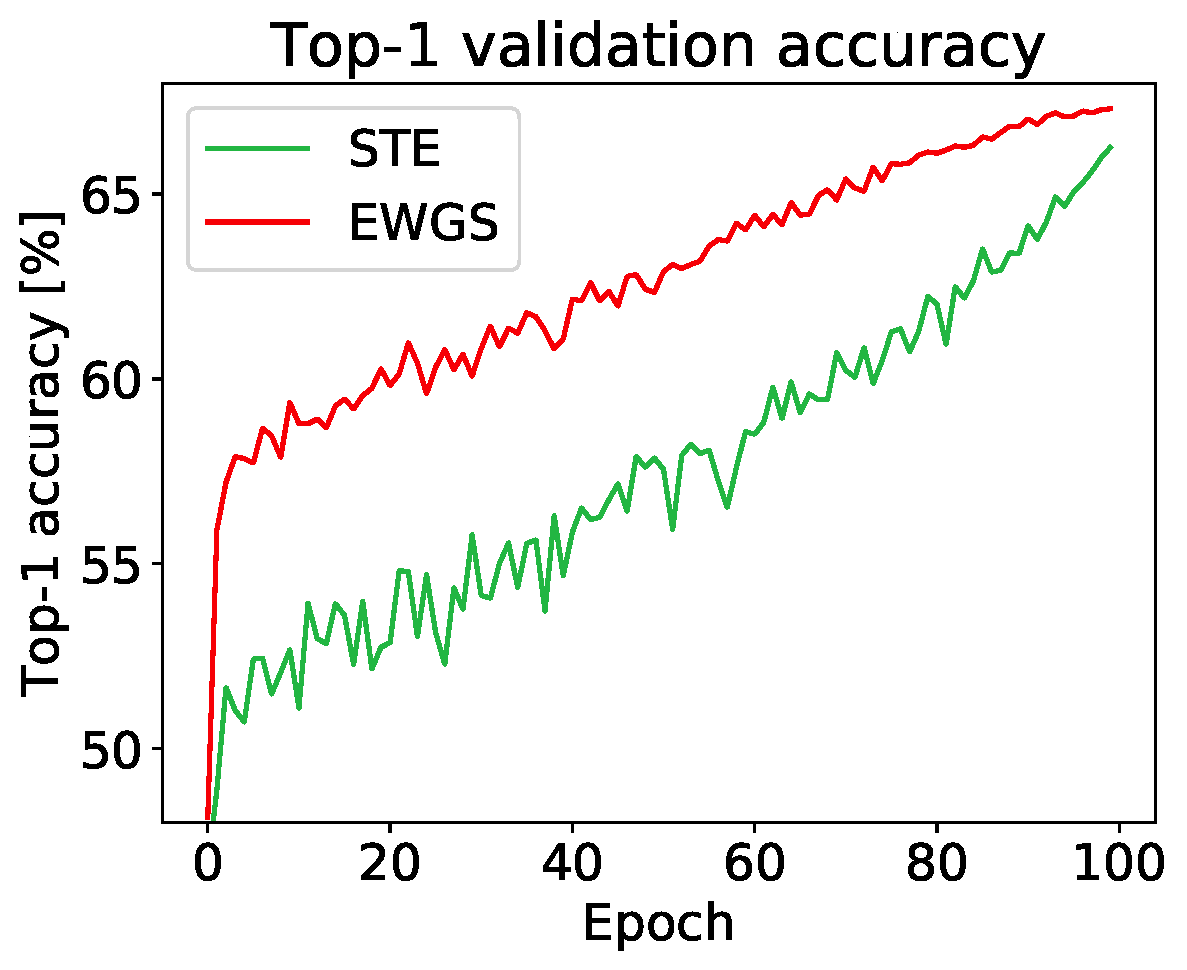
Experiment
Paper

|
J. Lee, D. Kim, B. Ham Network Quantization with Element-wise Gradient Scaling In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2021 [Paper on arXiv] |
BibTeX
@inproceedings{lee2021network,
author = "J. Lee, D. Kim, B. Ham",
title = "Network Quantization with Element-wise Gradient Scaling",
booktitle = "Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition",
year = "2021"
}
Acknowledgements
This research was supported by the Samsung Research Funding & Incubation Center for Future Technology (SRFC-IT1802-06).