Background-Aware Pooling and Noise-Aware Loss
for Weakly-Supervised Semantic Segmentation
(CVPR 2021)


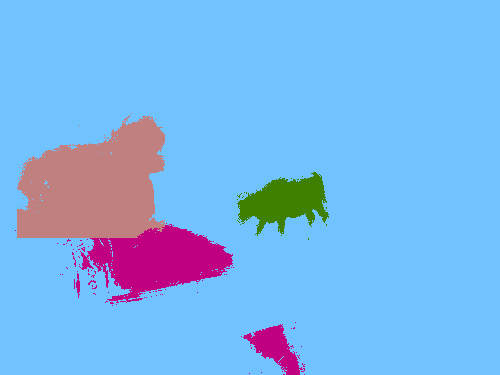

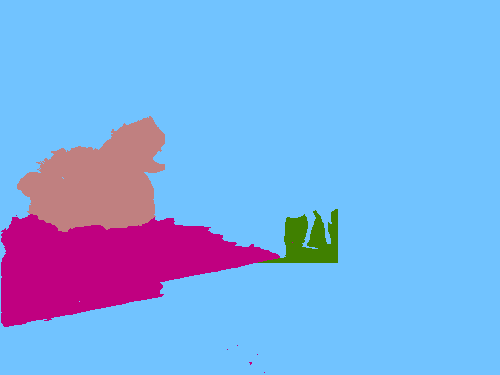
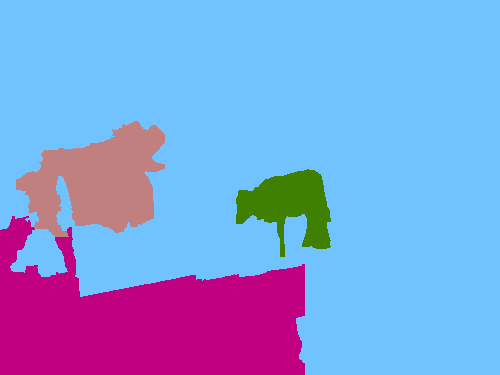

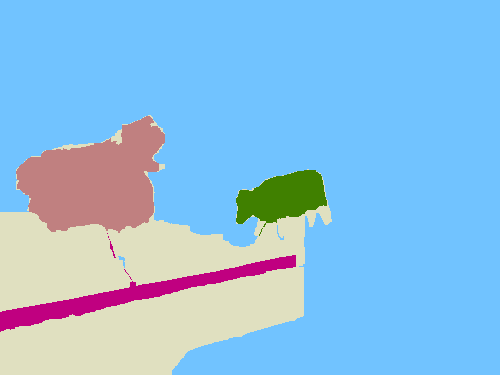
Visual comparison of pseudo ground-truth labels. Our approach generates better segmentation labels than other WSSS methods using object bounding boxes (WSSL and SDI). Hand-crafted methods (GrabCut and MCG) fail to segment object boundaries. For MCG, we compute intersection-over-union (IoU) scores using pairs of segment proposals and bounding boxes, and choose the best one for each box. Ours*: Ours with an indication of unreliable regions.
Abstract
We address the problem of weakly-supervised semantic segmentation (WSSS) using bounding box annotations. Although object bounding boxes are good indicators to segment corresponding objects, they do not specify object boundaries, making it hard to train convolutional neural networks (CNNs) for semantic segmentation. We find that background regions are perceptually consistent in part within an image, and this can be leveraged to discriminate foreground and background regions inside object bounding boxes. To implement this idea, we propose a novel pooling method, dubbed background-aware pooling (BAP), that focuses more on aggregating foreground features inside the bounding boxes using attention maps. This allows to extract high-quality pseudo segmentation labels to train CNNs for semantic segmentation, but the labels still contain noise especially at object boundaries. To address this problem, we also introduce a noise-aware loss (NAL) that makes the networks less susceptible to incorrect labels. Experimental results demonstrate that learning with our pseudo labels already outperforms state-of-the-art weakly- and semi-supervised methods on the PASCAL VOC 2012 dataset, and the NAL further boosts the performance.
Method overview
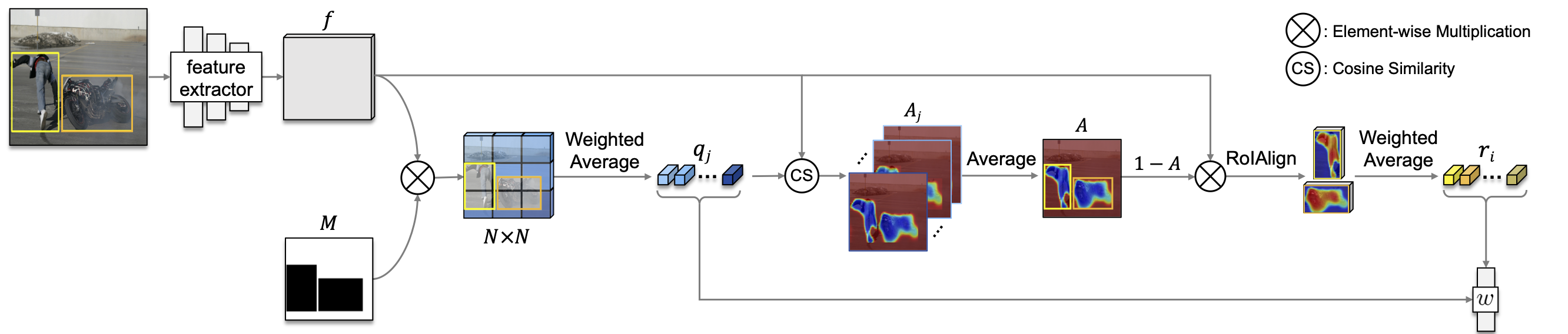
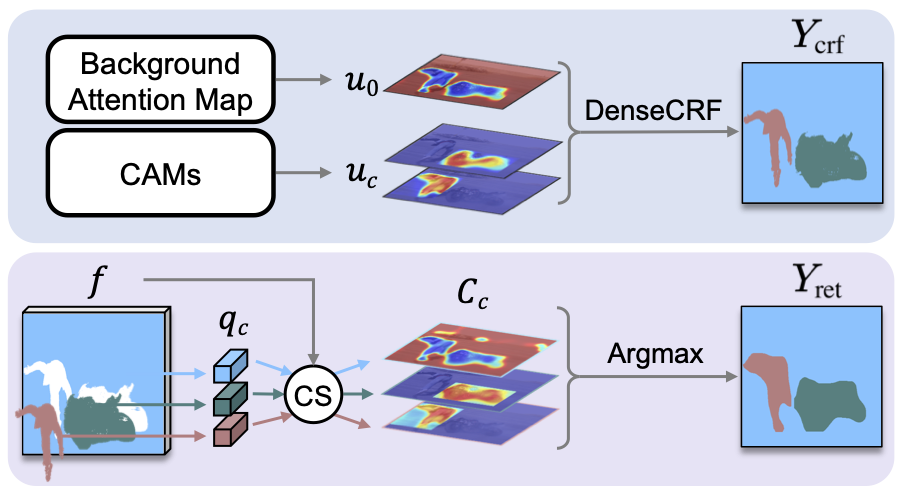
Our approach mainly consists of three stages: First, we train a CNN for image classification using object bounding boxes (Fig. 1). We use BAP leveraging a background prior, that is, background regions are perceptually consistent in part within an image, allowing to extract more accurate CAMs. To this end, we compute an attention map for a background adaptively for each image. Second, we generate pseudo segmentation labels using CAMs obtained from the classification network together with the background attention maps and prototypical features (Fig. 2). Finally, we train CNNs for semantic segmentation with the pseudo ground truth but possibly having noisy labels. We use a NAL to lessen the influence of the noisy labels.
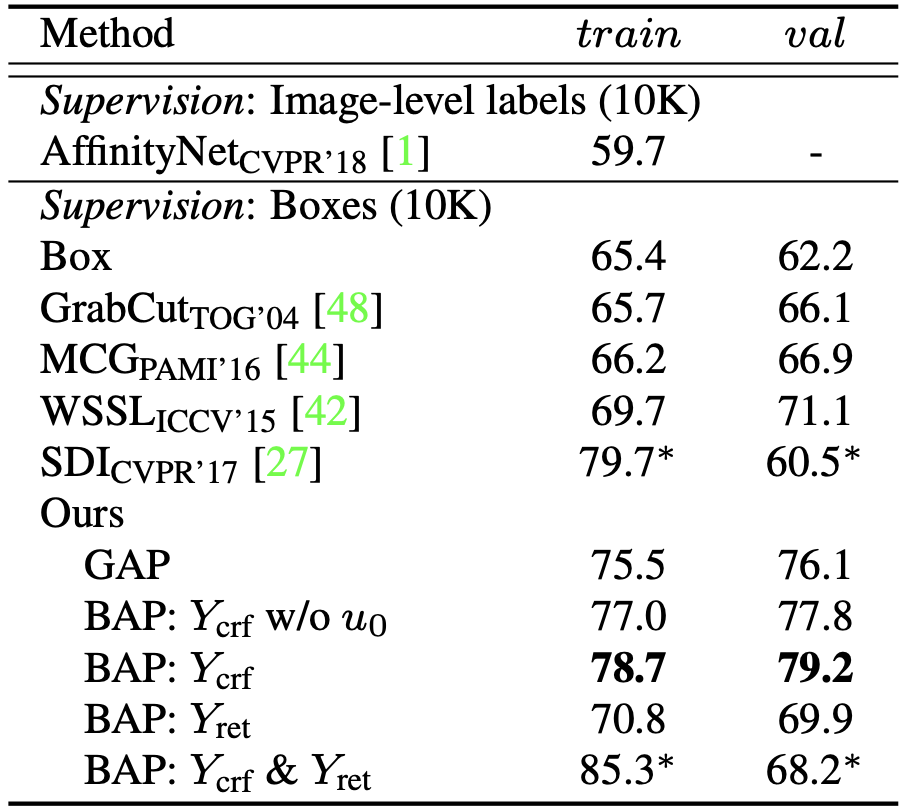
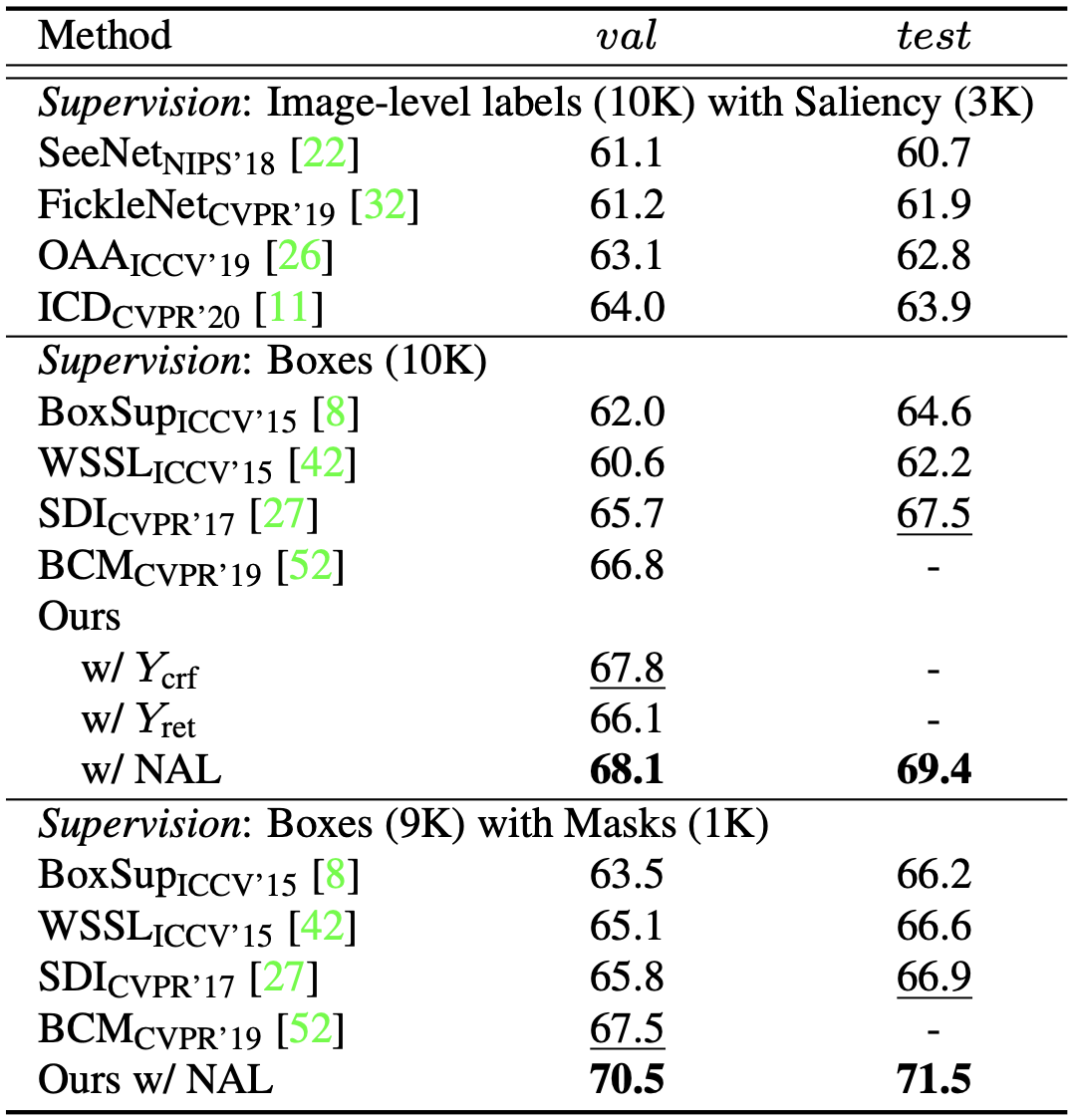
Experimental results
Paper

|
Background-Aware Pooling and Noise-Aware Loss for Weakly-Supervised Semantic Segmentation
Y. Oh, B. Kim, B. Ham In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2021 [arXiv] [Github] [BibTex] |
Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (NRF-2019R1A2C2084816).